Model 3 Architecture
I've been pondering a bit on web architecture and how component frameworks, such as JSF, should really be interpreted. Most developers are familiar with Model 1 and Model 2 architectures:
Taking from Sun Blueprint Guidelines, "A Model 1 architecture consists of a Web browser directly accessing Web-tier JSP pages. ... A Model 1 application control is decentralized, because the current page being displayed determines the next page to display."
Model 2 is described as, "A Model 2 architecture introduces a controller servlet between the browser and the JSP pages or servlet content being delivered. The controller centralizes the logic for dispatching requests to the next view based on the request URL, input parameters, and application state. The controller also handles view selection, which decouples JSP pages and servlets from one another."
I really don't think that from a developer standpoint, that true component frameworks fall into either of these categories since they draw from the "benefits" of both models. Model 1 architecture allows simplicity of development and removes the need to centralize control. With Model 2 architecture, you have the ability to decouple JSP pages from controller/business logic.
Let me explain how I interpret true component frameworks in relation to the points above:
To provide an example, lets say you have two different pages below, where the colored sections are identical components and the white boxes are different between the two pages:
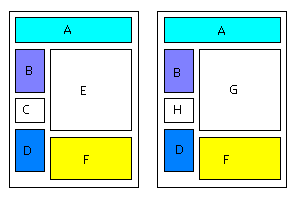
Each component acts as an independently of each other as stated above and for sake of discussion, component B is a search box and components E and G are sortable and pageable lists of data.
According to the items I've outlined above, a developer can simply drop component B into any page and get search capabilities without tying it's implementation to any specific page or 'Action'. Also, because components operate independently within their own state and lifecycle, components E and G can be paged and sorted without affecting the rest of the page or having to worry about managing the state of those other components such as the search box.
According to these rules, you can page component E to the third set of results and then submit an invalid query within the search box (B) and have component E preserve its state on the third set of results when the search box returns with an error.
Within current models, some search action would be called, and if it fails, it would have to figure out what page referred it and how to preserve whatever the original view was for all the rest of the features presented (such as pageable and sortable results). Of course, you can find ways using the HttpSession to preserve state in a request/page-agnostic manner, but the point is that you have to code specifically for these cases.
Where I feel that a true component model differs from some other people's concept of components is that they:
I would enjoy comments from others.
Taking from Sun Blueprint Guidelines, "A Model 1 architecture consists of a Web browser directly accessing Web-tier JSP pages. ... A Model 1 application control is decentralized, because the current page being displayed determines the next page to display."
Model 2 is described as, "A Model 2 architecture introduces a controller servlet between the browser and the JSP pages or servlet content being delivered. The controller centralizes the logic for dispatching requests to the next view based on the request URL, input parameters, and application state. The controller also handles view selection, which decouples JSP pages and servlets from one another."
I really don't think that from a developer standpoint, that true component frameworks fall into either of these categories since they draw from the "benefits" of both models. Model 1 architecture allows simplicity of development and removes the need to centralize control. With Model 2 architecture, you have the ability to decouple JSP pages from controller/business logic.
Let me explain how I interpret true component frameworks in relation to the points above:
- Similar to Model 1, any combination of components can be declared within a single view.
- As with Model 2 "actions", components are implemented in such a way that they decouple controller/business logic from the view.
- Components within a single view can operate and execute independent of each other.
- Components manage their own state within any number of request lifecycles
To provide an example, lets say you have two different pages below, where the colored sections are identical components and the white boxes are different between the two pages:
Each component acts as an independently of each other as stated above and for sake of discussion, component B is a search box and components E and G are sortable and pageable lists of data.
According to the items I've outlined above, a developer can simply drop component B into any page and get search capabilities without tying it's implementation to any specific page or 'Action'. Also, because components operate independently within their own state and lifecycle, components E and G can be paged and sorted without affecting the rest of the page or having to worry about managing the state of those other components such as the search box.
According to these rules, you can page component E to the third set of results and then submit an invalid query within the search box (B) and have component E preserve its state on the third set of results when the search box returns with an error.
Within current models, some search action would be called, and if it fails, it would have to figure out what page referred it and how to preserve whatever the original view was for all the rest of the features presented (such as pageable and sortable results). Of course, you can find ways using the HttpSession to preserve state in a request/page-agnostic manner, but the point is that you have to code specifically for these cases.
Where I feel that a true component model differs from some other people's concept of components is that they:
- Aren't part of a specific 'page' or 'action' as with centralized Model 2 architectures, but fall more in line with Model 1 architectures in that components decentralize requirements in a reusable manner.
- Components aren't simply glorified HTML decorators and they actually extend their life beyond rendering to the next request.
- Any component included in the view could drive application flow.
I would enjoy comments from others.
posted by Jacob Hookom at
11:23 PM
![]()
![]()

1 Comments:
This is exactly the approach I want to use on my current project.
I was reading about the future of the JSR 168 portlet spec at this link JSR 168 V2.0.
One interesting approach may be to use Portlets representing the user view of the application, implemented as JSF components. What do you think?
By Anonymous, at 10:23 PM
Anonymous, at 10:23 PM
Post a Comment
<< Home